|
WWW 2.1 Introduzione World Wide Web tra tutte le
applicazioni disponibili sulla rete Internet è quella che gode della
maggiore diffusione presso gli utenti, e che ne rappresenta per così
dire la 'punta di diamante'. Per moltissimi utenti essa coincide
addirittura con Internet. Se questa sovrapposizione, come sappiamo, è
tecnicamente scorretta, è pur vero che la maggior parte delle risorse
attualmente disponibili on-line si colloca proprio nel contesto del Web.
D'altra parte, anche se consideriamo il complesso di innovazioni
tecnologiche che negli ultimi anni hanno investito la rete modificandone
il volto, ci accorgiamo che la quasi totalità si colloca nell'area Web.
Per queste ragioni abbiamo ritenuto opportuno dedicare un intero
capitolo alla descrizione del funzionamento di World Wide Web e dei vari
linguaggi e sistemi su cui esso si basa. Quando fu concepito, il Web era
destinato ad una comunità di utenti limitata, non necessariamente in
possesso di particolari competenze informatiche ed editoriali, e non
particolarmente preoccupata degli aspetti qualitativi e stilistici nella
presentazione dell'informazione. Per questa ragione nello sviluppo
dell'architettura Web furono perseguiti espressamente gli obiettivi
della semplicità di implementazione e di utilizzazione. Queste caratteristiche hanno
notevolmente contribuito al successo del Web. Ma con il successo lo
spettro dei fornitori di informazione si è allargato: World Wide Web è
diventato un vero e proprio sistema di editoria elettronica on-line.
Ovviamente l'espansione ha suscitato esigenze e aspettative che non
erano previste nel progetto originale, stimolando una serie di revisioni
e di innovazioni degli standard tecnologici originari. Per ovviare al rischio di una 'babele
telematica' è stato costituito il World Wide Web Consortium
(W3C). Si tratta di una organizzazione no profit ufficialmente
deputata allo sviluppo degli standard tecnologici per il Web che
raccoglie centinaia di aziende, enti e centri di ricerca coinvolti più
o meno direttamente nel settore. In questi ultimi anni il W3C ha
prodotto una serie di specifiche divenute, o in procinto di divenire,
standard ufficiali su Internet. Tutti i materiali prodotti dal W3C sono
di pubblico dominio, e vengono pubblicati sul sito Web del consorzio. 2.2
Due concetti importanti: multimedia e ipertesto
I primi argomenti che è necessario
affrontare in una trattazione sul funzionamento di World Wide Web sono i
concetti di ipertesto e di multimedia. Il Web, infatti, può
essere definito come un ipertesto multimediale distribuito: è
dunque chiaro che tali concetti delineano la cornice generale nella
quale esso e tutte le tecnologie sottostanti si inseriscono. In primo luogo è bene distinguere il
concetto di multimedialità da quello di ipertesto. I due
concetti sono spesso affiancati e talvolta sovrapposti, ma mentre il
primo si riferisce agli strumenti della comunicazione, il secondo
riguarda la sfera più complessa della organizzazione dell'informazione. Con multimedialità, dunque, ci si
riferisce alla possibilità di utilizzare contemporaneamente, in uno
stesso messaggio comunicativo, più media e/o più linguaggi. Da questo
punto di vista, possiamo dire che una certa dose di multimedialità è
intrinseca in tutte le forme di comunicazione che l'uomo ha sviluppato e
utilizzato, a partire dalla complessa interazione tra parola e gesto,
fino alle tecnologie comunicative più recenti come il cinema o la
televisione. I documenti multimediali sono oggetti
informativi complessi e di grande impatto. Ma oltre che nella possibilità
di integrare in un singolo oggetto diverse forme di comunicazione, il
nuovo orizzonte aperto dal web risiede nella possibilità di dare al
messaggio una organizzazione molto diversa da quella cui siamo abituati
da ormai molti secoli. È in questo senso che la multimedialità
informatica si intreccia profondamente con gli ipertesti, e con
l'interattività. Vediamo dunque cosa si intende con il concetto di ipertesto. La definizione di questo termine
potrebbe richiedere un volume a parte (ed esistono realmente decine di
volumi che ne discutono!). Dal punto di vista logico un ipertesto è un
sistema di organizzazione delle informazioni (testuali, ma non solo) in
una struttura non sequenziale, bensì reticolare. A partire dalla invenzione della
scrittura alfabetica, e in particolare da quella della stampa,
l'organizzazione dell'informazione in un messaggio, e la corrispondente
fruizione della stessa, è essenzialmente basata su un modello lineare
sequenziale, su cui si può sovrapporre al massimo una strutturazione
gerarchica. Per capire meglio cosa intendiamo basta pensare ad un libro,
il tipo di documento per eccellenza della modernità: un libro è una
sequenza lineare di testo, eventualmente organizzato come una sequenza
di capitoli, che a loro volta possono essere organizzati in sequenze di
paragrafi, e così via. La fruizione del testo avviene pertanto in modo
sequenziale, dalla prima all'ultima pagina. Certo sono possibili
deviazioni (letture 'a salti', rimandi in nota), ma si tratta di
operazioni 'innestate' in una struttura nella quale prevale la linearità.
L'essenza stessa della razionalità e della retorica occidentale riposa
su una struttura lineare dell'argomentazione. Un ipertesto invece si basa su
un'organizzazione reticolare dell'informazione, ed è costituito da un
insieme di unità informative (i nodi) e da un insieme di collegamenti
(detti nel gergo tecnico link) che da un nodo permettono di
passare ad uno o più altri nodi. Se le informazioni che sono collegate
tra loro nella rete non sono solo documenti testuali, ma in generale
informazioni veicolate da media differenti (testi, immagini, suoni,
video), l'ipertesto diventa multimediale, e viene definito ipermedia.
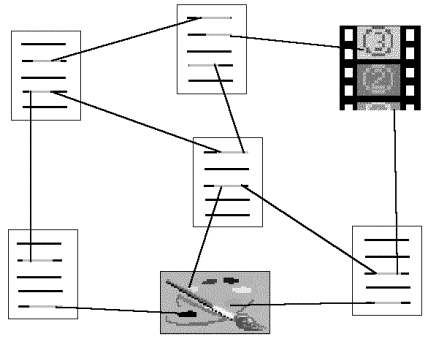
Una idea intuitiva di cosa sia un ipertesto multimediale può essere
ricavata dalla figura seguente.
I documenti, l'immagine e il filmato
sono i nodi dell'ipertesto, mentre le linee rappresentano i collegamenti
(link) tra i vari nodi: il documento in alto, ad esempio,
contiene tre link, da dove è possibile saltare ad altri documenti o
alla sequenza video. Il lettore, dunque, non è vincolato dalla sequenza
lineare dei contenuti di un certo documento, ma può muoversi da una
unità testuale ad un'altra (o ad un blocco di informazioni veicolato da
un altro medium) costruendosi ogni volta un proprio percorso di lettura.
Dal punto di vista della
implementazione concreta, un ipertesto digitale si presenta come un
documento elettronico in cui alcune porzioni di testo o immagini
presenti sullo schermo, evidenziate attraverso artifici grafici (icone,
colore, tipo e stile del carattere), rappresentano i diversi
collegamenti disponibili nella pagina. Questi funzionano come dei pulsanti
che attivano il collegamento e consentono di passare, sullo schermo, al
documento di destinazione. Il pulsante viene 'premuto' attraverso un
dispositivo di input, generalmente il mouse, una combinazioni di tasti,
o un tocco su uno schermo touch-screen. L'incontro tra ipertesto,
multimedialità e interattività rappresenta dunque la nuova frontiera
delle tecnologie comunicative. Il problema della comprensione teorica e
del pieno sfruttamento delle enormi potenzialità di tali strumenti,
specialmente in campo didattico, pedagogico e divulgativo (così come in
quello dell'intrattenimento e del gioco), è naturalmente ancora in gran
parte aperto: si tratta di un settore nel quale vi sono state negli
ultimi anni - ed è legittimo aspettarsi negli anni a venire -
innovazioni di notevole portata. 2.3
L'architettura e i protocolli di World Wide Web
Il concetto di ipertesto descrive la
natura logica di World Wide Web. Si tratta infatti di un insieme di documenti
multimediali interconnessi a rete mediante molteplici collegamenti
ipertestuali e memorizzati sui vari host che costituiscono Internet.
Ciascun documento considerato dal punto di vista dell'utente viene
definito pagina Web, ed è costituito da testo, immagini fisse e
in movimento, in definitiva ogni tipo di oggetto digitale. Di norma le
pagine Web sono riunite in collezioni riconducibili ad una medesima
responsabilità autoriale o editoriale, e talvolta, ma non
necessariamente, caratterizzate da coerenza semantica, strutturale o
grafica. Tali collezioni sono definiti siti Web. Se consideriamo
il Web come un sistema di editoria on-line, i singoli siti possono
essere assimilati a singole pubblicazioni. Attivando uno dei collegamenti
contenuti nella pagina correntemente visualizzata, essa viene sostituita
dalla pagina di destinazione, che può trovarsi su un qualsiasi computer
della rete. In questo senso utilizzare uno strumento come Web permette
di effettuare una sorta di navigazione in uno spazio informativo
astratto, uno degli esempi del cosiddetto ciberspazio. Ma quali tecnologie realizzano tale
spazio astratto? In linea generale l'architettura informatica di World
Wide Web non differisce in modo sostanziale da quella delle altre
applicazioni Internet. Anche in questo caso, infatti, ci troviamo di
fronte ad una sistema basato su una interazione client-server,
dove le funzioni elaborative sono distribuite in modo da ottimizzare
l'efficienza complessiva. Il protocollo di comunicazione tra client e
server Web si chiama HyperText Transfer Protocol (HTTP). Si
tratta di un protocollo applicativo che a sua volta utilizza TCP/IP per
inviare i dati attraverso la rete. A differenza di altre applicazioni
Internet, tuttavia, il Web definisce anche dei formati o linguaggi
specifici per i tipi di dati che possono essere inviati dal server al
client. Tali formati e linguaggi specificano la codifica dei vari
oggetti digitali che costituiscono un documento, e il modo di
rappresentare i collegamenti ipertestuali che lo legano ad altri
documenti. Tra essi ve ne è uno che assume un ruolo prioritario nel
definire struttura, contenuto e aspetto di un documento/pagina Web:
attualmente si tratta del linguaggio HyperText Markup Language (HTML). Un client Web costituisce lo
strumento di interfaccia tra l'utente e il sistema Web; le funzioni
principali che esso deve svolgere sono:
I client Web vengono comunemente
chiamati browser, dall'inglese to browse, scorrere,
sfogliare, poiché essi permettono appunto di scorrere le pagine
visualizzate. Un server Web, o più precisamente server
HTTP, per contro, si occupa della gestione, del reperimento e
dell'invio dei documenti (ovvero dei vari oggetti digitali che li
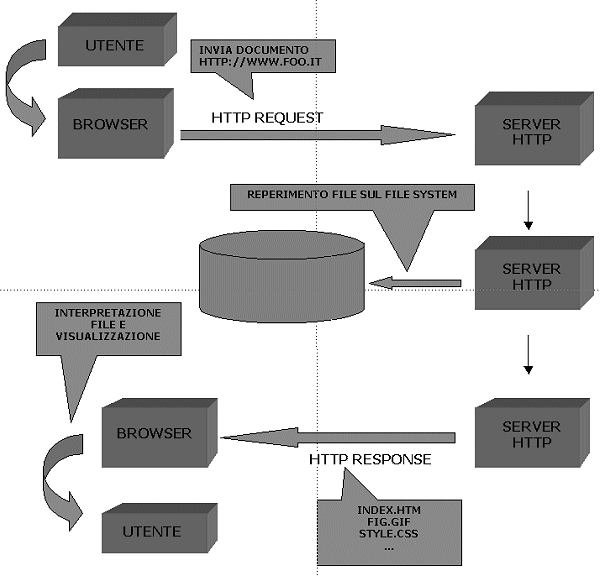
costituiscono) richiesti dai client. Nel momento in cui l'utente attiva
un collegamento - agendo su un link - o specifica esplicitamente
l'indirizzo di un documento, il client invia una richiesta HTTP (HTTP
request) al server opportuno con l'indicazione del documento che
deve ricevere. Questa richiesta viene interpretata dal server, che a sua
volta invia gli oggetti che compongono il documento richiesto corredati
da una speciale intestazione HTTP che ne specifica il tipo. Tale
specificazione si basa sui codici di tipo definiti dalla codifica MIME
(o MIME type), nata per la posta elettronica. Se necessario, il
server prima di inviare i dati può effettuare delle procedure di
autenticazione, in modo da limitare l'accesso a un documento a utenti
autorizzati e in possesso di password.
2.4
I linguaggi del Web
Come abbiamo anticipato nel paragrafo
precedente, a differenza delle altre applicazioni Internet, World Wide
Web, oltre ai protocolli applicativi, definisce anche dei formati
specifici per codificare i documenti che vi vengono immessi e
distribuiti. I documenti che costituiscono la rete
ipertestuale del Web sono principalmente documenti testuali, ai quali
possono essere associati oggetti grafici (fissi o animati) e in taluni
casi moduli software. In generale, comunque, struttura, contenuti e
aspetto di una pagina Web visualizzata da un dato browser sono
definiti interamente nel documento testuale che ne costituisce l'oggetto
principale. Tale definizione attualmente si basa
su uno speciale linguaggio di rappresentazione dei documenti in formato
elettronico, appartenente alla classe dei markup language
(linguaggi di marcatura), denominato HyperText Markup Language (HTML).
La formalizzazione di HTML, effettuata da uno dei gruppi di lavoro del
W3C, è oggi completamente stabilizzata e tutti i browser disponibili
sono in grado di interpretarne la sintassi e di rappresentare
opportunamente i documenti in base ad essa codificati. 2.4.1 HyperText Markup Language
HyperText Markup Language (HTML) è
il formato in cui sono memorizzati i documenti ipermediali del Web. Si
tratta di un linguaggio di marcatura (markup language),
appositamente orientato alla descrizione di documenti testuali. Ma cosa vuol dire 'linguaggio di
marcatura'? L'idea di 'markup' in un documento elettronico si ricollega
alla simbologia che scrittori e correttori di bozze utilizzano nella
stampa tradizionale per indicare al compositore ed al tipografo come
trattare graficamente le parti di testo che svolgono funzioni
particolari: ad esempio, la sottolineatura per indicare il corsivo. In
modo simile, i linguaggi di marcatura sono costituiti da un insieme di
istruzioni, dette tag (marcatori), che servono a
descrivere la struttura, la composizione e l'impaginazione del
documento. I marcatori sono sequenze di normali caratteri, e vengono
introdotti, secondo una determinata sintassi, all'interno del documento,
accanto alla porzione di testo cui si riferiscono. Un documento HTML è dunque un file
in formato testo che include, insieme al contenuto testuale vero e
proprio, i marcatori che ne descrivono la struttura. Ad esempio è
possibile indicare i diversi livelli dei titoli di un documento, lo
stile dei caratteri (corsivo, grassetto...), i capoversi, la presenza di
liste (numerate o no). Volendo realizzare un documento ipermediale,
avremo a disposizione anche marcatori specifici per la definizione dei
link ipertestuali e per l'inserimento di immagini. Naturalmente le
immagini non sono parte integrante del file HTML, che in quanto tale è
un semplice file di testo. I file grafici vengono inviati come oggetti
autonomi dal server, ed inseriti in una pagina Web solo durante
l'operazione di visualizzazione effettuata dal browser. I formati di
immagini digitali standard su Web sono il GIF ed il JPEG. Si tratta di
sistemi di codifica grafica in grado di comprimere notevolmente la
dimensione del file, e pertanto particolarmente adatti ad un uso su
rete.
Un utente di Internet che desiderasse
solo consultare e non produrre informazione in rete potrebbe fare a meno
di preoccuparsi del funzionamento di HTML. Attenzione, però: una delle
caratteristiche fondamentali di Internet è proprio l'estrema facilità
con la quale è possibile diventare protagonisti attivi dello scambio
informativo. Se si vuole compiere questo salto decisivo, un minimo di
familiarità con HTML è necessaria. Non occorre avere timori
reverenziali: HTML non è un linguaggio di programmazione, e le sue
istruzioni di base sono semplicissime: imparare i primi rudimenti di
HTML non è più complicato che imparare a usare e a interpretare le
principali sigle ed abbreviazioni usate dai correttori di bozze. HTML è nato e si è sviluppato
insieme a World Wide Web. Nella prima versione, il linguaggio non
prevedeva la possibilità di rappresentare fenomeni testuali ed
editoriali complessi. Di conseguenza le sue specifiche hanno subito
diverse revisioni ed estensioni, che hanno dato origine a diverse
versioni ufficiali, nonché ad una serie di estensioni introdotte dai
vari produttori di Web browser commerciali. Tuttavia, mentre le commissioni
ufficiali lavoravano lentamente alla revisione dello standard,
l'esplosione del fenomeno Internet, e la diffusa richiesta di strumenti
capaci di rendere spettacolari (più che 'documentalmente' ben
strutturate) le pagine Web, hanno indotto le industrie produttrici di
browser, ad introdurre una serie di estensioni individuali al
linguaggio. La speranza (nel caso di Netscape, coronata da un certo
successo nei primi anni) era anche quella di conquistare una posizione
di monopolio di fatto nel mercato, dato che le estensioni introdotte da
una determinata industria erano, almeno in prima istanza, riconosciute e
interpretate correttamente solo dal relativo browser. La più recente versione ufficiale
del linguaggio rilasciata dal W3C, denominata HTML 4.0, ha riportato un
certo ordine, accogliendo molte delle innovazioni più interessanti. 2.4.2 Uniform Resource Locator
Un aspetto particolare del
funzionamento di World Wide Web è la tecnica di indirizzamento dei
documenti, ovvero il modo in cui è possibile far riferimento ad un
determinato documento tra tutti quelli che sono pubblicati sulla rete. La soluzione che è stata adottata
per far fronte a questa importante esigenza si chiama Uniform
Resource Locator (URL).
La 'URL' di un documento corrisponde in sostanza al suo indirizzo
in rete; ogni risorsa informativa (computer o file) presente su Internet
viene rintracciata e raggiunta dai nostri programmi client attraverso la
sua URL. Prima della introduzione di questa tecnica non esisteva alcun
modo per indicare formalmente dove fosse una certa risorsa informativa
su Internet. Una URL ha una sintassi molto
semplice, che nella sua forma normale si compone di tre parti: tiposerver://nomehost/nomefile La prima parte indica con una parola
chiave il tipo di server a cui si punta (può trattarsi di un server
gopher, di un server http, di un server FTP, e così via); la seconda
indica il nome simbolico dell'host su cui si trova il file indirizzato;
al posto del nome può essere fornito l'indirizzo numerico; la terza
indica nome e posizione ('path') del singolo documento o file a cui ci
si riferisce. Tra la prima e la seconda parte vanno inseriti i caratteri
'://'. Un esempio di URL è il seguente: http://www.liberliber.it/index.html La parola chiave 'http' segnala che
ci si riferisce ad un server Web, che si trova sul computer
denominato 'www.liberliber.it', dal quale vogliamo che ci venga inviato
il file in formato HTML il cui nome è 'index.html'. Mutando le sigle è
possibile fare riferimento anche ad altri tipi di servizi di rete
Internet:
Occorre notare che
questa sintassi può essere utilizzata sia nelle istruzioni ipertestuali
dei file HTML, sia con i comandi che i singoli client, ciascuno a suo
modo, mettono a disposizione per raggiungere un particolare server o
documento. È bene pertanto che anche il normale utente della rete
Internet impari a servirsene correttamente. 2.5 Alcuni programmi per l'uso di
World Wide Web
2.5.1 Introduzione Lo strumento principale per la
navigazione nelle pagine del World Wide Web è, abbiamo ricordato più
volte, un 'browser', ovvero un programma in grado di richiedere la
pagina che desideriamo raggiungere al server remoto che la ospita,
riceverla e visualizzarla correttamente (testo, immagini, collegamenti
ipertestuali, sfondi... il tutto impaginato seguendo le istruzioni
fornite, sotto forma di marcatori HTML, da chi ha creato quella
determinata pagina). I primi browser Web (come Mosaic) sono nati nei
laboratori di ricerca delle università. L'esplosione del fenomeno
Internet, in gran parte legata proprio a World Wide Web, ha determinato
il moltiplicarsi delle iniziative per sviluppare nuovi programmi, o
migliorare quelli esistenti, e in particolare ne ha mostrato le
potenzialità commerciali. Questo ha attirato l'attenzione di molte case
produttrici di software, e ha indotto moltissimi dei pionieri
universitari a fondarne di nuove (il caso più clamoroso è quello della
più volte citata Netscape Corporation). Attualmente in questo settore
si sta combattendo una delle battaglie strategiche per il futuro
dell'informatica e della telematica. Conseguentemente i programmi per
accedere a World Wide Web oggi disponibili sono abbastanza numerosi,
alcuni gratuiti, altri venduti con particolari formule commerciali. Come
per gli altri servizi di rete visti finora, esistono browser per tutte
le più diffuse piattaforme e sistemi operativi. L'utilizzazione di questi programmi,
in linea di massima, è piuttosto facile: basta un semplice click del
mouse, per collegarsi con un computer che è all'altro capo del mondo.
Inoltre, un buon client Web può accedere in maniera del tutto
trasparente ai server FTP, mostrare i messaggi dei newsgroup, gestire la
posta elettronica e, come vedremo, le versioni più recenti possono
anche ricevere automaticamente 'canali' informativi attraverso il
meccanismo dell'information push. Un client Web può insomma integrare
fra loro le principali funzionalità messe a disposizione da Internet.
Una volta attivato il collegamento alla rete, basta avviare il client
sul proprio computer e iniziare la navigazione tra i milioni di server
Web sparsi su Internet. Nelle pagine che seguono passeremo in
rassegna le funzionalità comuni a tutti i più diffusi browser. Ma
ricordate che in questo campo lobsolescenza degli strumenti è
rapidissima, quindi non vale la pena di prendere in esame un particolare
client poiché non è detto che dopo sei mesi si utilizzi ancora
quello!. L'unico consiglio che ci sentiamo di dare senza timore è
questo: la via migliore per imparare ad utilizzare tutti gli strumenti
del mondo di Internet è quella di usarli, spinti da una buona dose di
curiosità. O, per dirla con Galilei, "provando e riprovando". 2.5.2
La famiglia dei browser grafici
I due browser grafici attualmente più
evoluti e diffusi sono Internet Explorer e Netscape Navigator.
Entrambi sono programmi 'multiuso', capaci di offrire efficienti moduli
client per la gestione della posta elettronica e dei newsgroup, e per il
trasferimento di file via FTP. In queste pagine ci occuperemo della loro
caratteristica più importante, quella di strumento di consultazione
delle pagine Web. Entrambi i browser sono in grado di interpretare
uniformemente la maggior parte delle istruzioni previste nelle più
recenti specifiche del linguaggio HTML. Invece esiste una certa
difformità sul supporto delle estensioni a questo insieme, alimentata
dalla guerra commerciale esistente fra Microsoft e Netscape. Tutti i browser grafici dellultima
generazione hanno alcune caratteristiche comuni:
Cominciamo con gli elementi
dell'interfaccia utente. In primo luogo la barra del titolo, nella parte
superiore della finestra, permette di leggere il titolo del documento.
Ci sono poi la consueta barra dei menu, quella dei pulsanti, a cui si
aggiungono una barra che mostra la URL del documento visualizzato, e una
barra dei siti di uso frequente. Il documento Web viene reso nella
finestra principale in modalità grafica. Le varie sezioni del testo
sono formattate con stili e tipi di carattere diversi. In particolare le
porzioni di testo che attivano i link sono evidenziate dal cambiamento
di colore del carattere, eventualmente associato alla sottolineatura. Il
colore standard dei link disponibili in una pagina è il blu; ma la
maggior parte dei browser è in grado di interpretare le istruzioni del
linguaggio HTML che consentono di ridefinire il colore dei link. Per
attivare un collegamento è sufficiente posizionare il puntatore su una
porzione di testo o su un'immagine attivi (e cioè collegati
ipertestualmente ad altri documenti in rete), e premere il tasto
sinistro del mouse. In genere, nel momento in cui il cursore transita su
una porzione di testo o su un'immagine attivi, la sua forma cambia da
quella di una freccia a quella di una manina che indica. Oltre ai link ipertestuali
all'interno del documento, i browser mettono a disposizione una serie di
strumenti di supporto alla navigazione. Le altre operazioni fondamentali
che l'utente può effettuare sono le seguenti:
Queste funzioni sono attivabili
attraverso la barra di pulsanti o i comandi dei menu a tendina. La lista
dei segnalibri è uno degli strumenti più utili. Si tratta di una lista
di puntatori che può essere richiamata, in qualsiasi client, tramite un
menu a tendina o una apposita finestra. Le voci dei segnalibri contenute
nel menu corrispondono ai titoli delle pagine nella barra del titolo.
Sia Netscape che Internet Explorer consentono di personalizzare la
propria lista di segnalibri, strutturandola in cartelle e sottocartelle. Oltre ai comandi per la navigazione
sono disponibili anche alcune funzionalità standard: la memorizzazione
su disco del documento corrente, la stampa, la visualizzazione del file
sorgente in formato HTML. In generale i browser, oltre al
formato HTML, sono in grado di visualizzare autonomamente i file di
testo ed almeno i due formati di file grafici più diffusi su Internet:
il GIF e il JPEG, integrando le immagini all'interno del documento. Se il file che viene ricevuto dalla
rete è in un formato che il browser non sa interpretare direttamente,
ma che comunque 'conosce' perché associato a un altro programma
disponibile nel sistema, esso può avviare automaticamente delle
applicazioni di supporto in grado di interpretarlo: se si tratta di un
file sonoro verrà avviato un riproduttore di suoni, se si tratta di un
video verrà avviato un programma di riproduzione video, e così via.
L'utente può aggiungere quanti visualizzatori esterni desidera,
attraverso le procedure di configurazione di ogni singolo browser.
Qualora non fosse disponibile un programma per un dato formato, è
possibile memorizzare il file sull'hard disk locale. Una ulteriore
possibilità nella gestione di formati di file non standard è data dai plug-in,
dei moduli software che si integrano pienamente con il browser. La maggior parte dei browser
condividono anche alcune caratteristiche tecnologiche che rendono più
efficiente l'accesso on-line alle pagine, specialmente per chi usa una
linea telefonica:
La prima caratteristica si riferisce
al modo in cui il browser gestisce i file che vengono inviati dal server
remoto, e alle precedenze nella composizione a video della pagina. Come
abbiamo detto i file HTML sono dei semplici file in formato testuale e
hanno generalmente una dimensione in byte molto contenuta. I file
grafici invece, anche se usano uno dei cosiddetti algoritmi di
compressione, sono molto più esosi nell'occupazione di spazio.
Quando una pagina Web viene inviata, il file di testo arriva quindi
molto più velocemente dei file grafici eventualmente a corredo. Per
evitare tempi morti, e poiché si può assumere che un utente sia, in
genere, interessato alla lettura del testo prima che alla visione delle
immagini, molti browser cominciano subito a visualizzare il testo, anche
prima che tutte le immagini vengano ricevute completamente. E il testo
stesso viene visualizzato progressivamente, man mano che arrivano i
dati, senza aspettarne la ricezione completa. Questo meccanismo aumenta
notevolmente la velocità di una navigazione. La memoria di deposito, o cache
memory, è invece una sorta di duplicato locale di piccole sezioni
del World Wide Web. L'uso della cache permette di velocizzare un
eventuale nuovo accesso a pagine già visitate precedentemente, o a file
già caricati. Ogni volta che il browser riceve dalla rete una pagina,
fa una copia di tutti i file che la compongono sul disco rigido locale.
Se nel seguito della navigazione l'utente contatta di nuovo quella
medesima pagina, il programma carica i file memorizzati nella cache,
piuttosto che richiederli al server remoto. Il meccanismo funziona anche
se lo stesso file ricorre in più pagine: ad esempio le icone che si
ripetono su tutte le pagine di un certo sito. La disponibilità e la
dimensione della memoria cache sono modificabili attraverso i comandi di
configurazione del browser. Dopo un determinato periodo di tempo, o
quando lo spazio disponibile sul disco viene esaurito, il browser
cancella i file più vecchi, per fare spazio a quelli nuovi. I proxy server
estendono il meccanismo della memoria cache locale. Un proxy server è
un software che viene di norma installato su uno dei computer di una
rete locale collegata ad Internet. La sua funzione è quella di
conservare in un apposito archivio una copia di ogni file richiesto
dagli utenti che accedono alla rete (l'archivio può avere dimensioni
variabili a seconda della capacità di memoria del sistema su cui
risiede). Quando un utente richiede di accedere ad una data risorsa, il
suo browser contatta in primo luogo il proxy server (come dice il nome,
prossimo, e dunque molto più veloce): se le informazioni sono già
presenti nella memoria locale, il proxy le invia senza stabilire il
collegamento con i computer remoti (o stabilendo un collegamento assai
rapido al solo scopo di verificare che i file richiesti non siano nel
frattempo stati modificati); altrimenti effettua la normale procedura di
trasferimento remoto, e prima di recapitare i dati al computer chiamante
ne conserva una copia.
|